la fête de la science « Réalité Virtuelle »

Nous présenterons deux animations interactives :
-
Découvrez une méthode innovante de conception de nouveaux véhicules grâce à la maquette numérique. A vous de concevoir la voiture du futur !
-
Testez notre « nouvelle interface invisible » pour les jeux vidéos avant Noël ! « AceSpeeder 2 » est un nouveau jeu de course anti-gravité. Vous pouvez jouer à ce jeu soit avec une manette classique, soit avec votre corps. GPUVision, la technologie qui détecte la position du joueur, est développée à Laval.
Village de sciences devant le CCSTI, musée des sciences samdi 14 octobre: 10h00-18h00 dimanche 15 octobre: 14h-18h00
Laboratoire P&I ENSAM / Master RV / ESCIN CNAM / Pays de la Loire —–
科学祭
突然フランス語のエントリーとかするとアレなんですけど、今週末、「Fete de la science」つまり科学祭に参加します。
フランス国内の大学とか研究所がいっせいに行うイベントなのですが、新参研究室な我々ENSAM P&I Labは声もかかってなかったので、お願いして混ぜてもらうことにしました。
市内のmusee des sciences(科学博物館)で土日展示です。Laval Virtual会場の前にある科学館です。いまちょうど、企画展で「arts & sciences」をやっているようですのでその入り口のエリアにテントを立てる感じで設営。
先日、打ち合わせに行ったらFrance Bleu(ラジオ局)のインタビューを受けてしまいました。照れるYazidに「Nintendo Wiiよりも先に、新しいインタフェースをプレイ!」などと言わせてみました。
ちなみにESIEAからはロボカップのロボットが出てくるようです。おそらくロボクラブの学生。フランス・ベルギーの国際協議会(300チームぐらい出場する)でも上位に残るぐらいの強豪らしいです。
お客さんは科学館前だけで2-3000人は来るとのこと。お天気が毎日嵐なので心配ですが…で、私としては、こんなチャンスを逃すわけには行かないので、デモを2つ用意して貴重なデータを取りに行く、という状態です。
ふあー忙しいよー!! IVRC学生の旅行準備もあるし…ちょっときついですね。 —–
Google Docs & Spreadsheet!!
今日、Google Spreadsheetで仕事してたらいきなりシステムが変わってた。 なんと「Google Docs & Spreadsheet」になってる!!
http://docs.google.com/
これでExcelに加えてWordが要らなくなってしまいました(Excelのグラフ機能だけ…)。
ちなみにWordそのまんま、というわけではなくて、差分(リビジョン)機能とかWeb公開(Publish)機能とか、コラボレーション機能があるので、もしかするとWordより便利かもしれません。
しかもHTMLベースで、タグも直接かけます(セキュリティ的に大丈夫なのかしらん)。エクスポートはHTML、DOC、RTF、PDFをサポートしてます。
泣けるのは軽快なスペルチェッカーとワードカウント機能を備えているという点です。
もう論文の共著はWikiじゃなくなっちゃうかもしれませんねえ…。 極秘文書以外はここで書きそう。
ちなみに不満も無いことは無くて、SpreadsheetはLinux環境ではなぜか遅い、ということですかね(Ubuntu+Firefoxでの体感速度、しかもよく切れる)。
あと、一つ前のバージョンからGmailアカウントが無いと使えなくなったみたい。以前はメールで鍵付のURLを送るだけで編集できたし、Gmail以外のアカウントも利用可能だったんだけど、やっぱりセキュリティ上、仕様変更されたみたい(許可されていないGmailアカウントだと白紙になる)。
というわけで共著者の皆さん、移行しましょう…。
アランケイのポップカルチャー
後藤貴子さんという方のPCWATCHの記事
「後藤貴子の米国ハイテク事情」 -コンピュータは人間を進化させるか- アラン・ケイ氏インタビュー http://pc.watch.impress.co.jp/docs/2006/0925/high43.htm
アランケイにとっての「ポップカルチャー」ってずいぶん広いんだな。 でもそうだとすると、現実はポップさが足りないと思う。 もっと爆発的にゲリラ的に、革命的で怠惰な行動をしなければ。
それから「学習」について。 元のインタビューは「learning」とか言っているのだろうか? knowledgeを得ることがlearningというわけではないだろうに。 なんだかアランケイ自身の科学リテラシーに興味がわく。
「Googleで検索できたから知った気になる」という指摘はもっともだけれども、Squeakやアランケイが描いた絵というのは、「ちょっと自分でやれたからやった気になる」というのにも似ている気もする。
イマジネーションをコンピュータの上で簡単にする、プログラミング言語を使わない、という方向は時として学ぶ姿勢を怠惰にし、鳥かごの中でしか学べなくすることにもなる。
もちろん否定しているわけじゃない、同じ課題だけど正反対だ、というだけの話。
カエルの話はなんだかよくわからないけど、ポップカルチャーに目をむけよ、というのはよく理解できる。文化や風習、無法や奇襲は、カオスなコンピュータの歴史の本質だから。
それにしてもGoogleで「Engelbart」を検索しても日本語版だと怖いことに http://del.icio.us/tag/engelbart が3番目にヒットしてしまう。 おそらく見せたかったのはこれだと思う。 http://sloan.stanford.edu/mousesite/1968Demo.html リアルプレイヤーが必要な時点でやる気半減するが、BGV代わりにかけておくとかっこいい。
2020-07-26追記
上記のDouglas C. Engelbart のデモ、移動してました。 Flash Playerが使えるうちに観ておくといいかも。 https://web.stanford.edu/dept/SUL/library/extra4/sloan/mousesite/1968Demo.html
補足。
今日になって気がついたんですが、 researchってre-searchですよね。 過去の研究や思い付きを、「再検索」するところから研究は始まるのかも。 「再発明」では困るけど。
補足の補足。
(…SqueakはSmallTalk風味というmixiでの流れがあります…) うーん
プログラミング言語って生き物なので 5年とか10年とかの時間で、どんどん変わって行ってしまうのですよね。 特にそのプログラミング言語のユーザの人口と文化にも依存するし。
たとえばPHPはスクリプト言語だけどオブジェクト指向、ほぼ同じことができる&同じ時期に生きたVBScriptはオブジェクト指向で書こうと思えば書けるけど、とても重い。 当のPHPだって、Python,Rubyのほうがエレガントに見える事もある。動作速度ではperlに負けることも多々あるし。 COBOLは20年たったって手続き型言語(OOCOBOLとかありますけど)。でも、それでいい業務、というのがあるから成立するわけですよね。
Squeakは一種のFlashだ、と思えばかなりハッピーな環境だと思います。
そういう意味ではアランはいつだって自分のプロジェクトを自分色に染めすぎ。それがSqueakの唯一の欠点かもしれない。まあヒッピー文化なのかもしれないけど。
思想・主義主張がある工業デザインというのは受け入れられるけど(買うか買わないかだから…)、思想・主義主張があるプログラミング言語、というのは時に開発者を自己満足の谷に落としてしまうのです。
3DSMax8フランス語版
いままで逃げに逃げてきたのだが、やっぱりMaxじゃないと駄目なことが多いので、仕方なくフランス語版を使ってる。
昔からある機能は場所が変わってないのでそれほど苦労しないでも(勘で)利用できる。…まあ楽ではないけれど。
難しかったのは、新機能関連。 以下Max8のスカイライト、グローバルイルミネーション関連メモ。
Creer panel -> Lumiere -> Standard -> “Dome de Lum.” クリエイトパネルの照明、スタンダードグループの「ドーム照明」
適当に床とか配置。
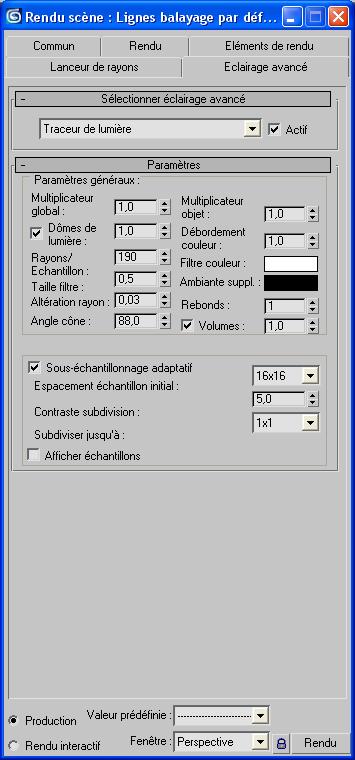
Rendu menu -> Eclairage avance -> Traceur de lumiere… レンダリングメニュー→アドバンス照明→レイトレーシング
Rayons/Echantillon: 250 -> 190 サンプリング数を190に Rebonds: 0 -> 1 バウンスを1回に Actif: check onにするとGIになる



たったこれだけのことなんだけど、かなり前進。 やっぱGIは見た目の印象が全然違うからねえ。
OpenCVで顔画像認識
ついさっきまでMaxの話を書いていたわけですが、いまはプログラミング。
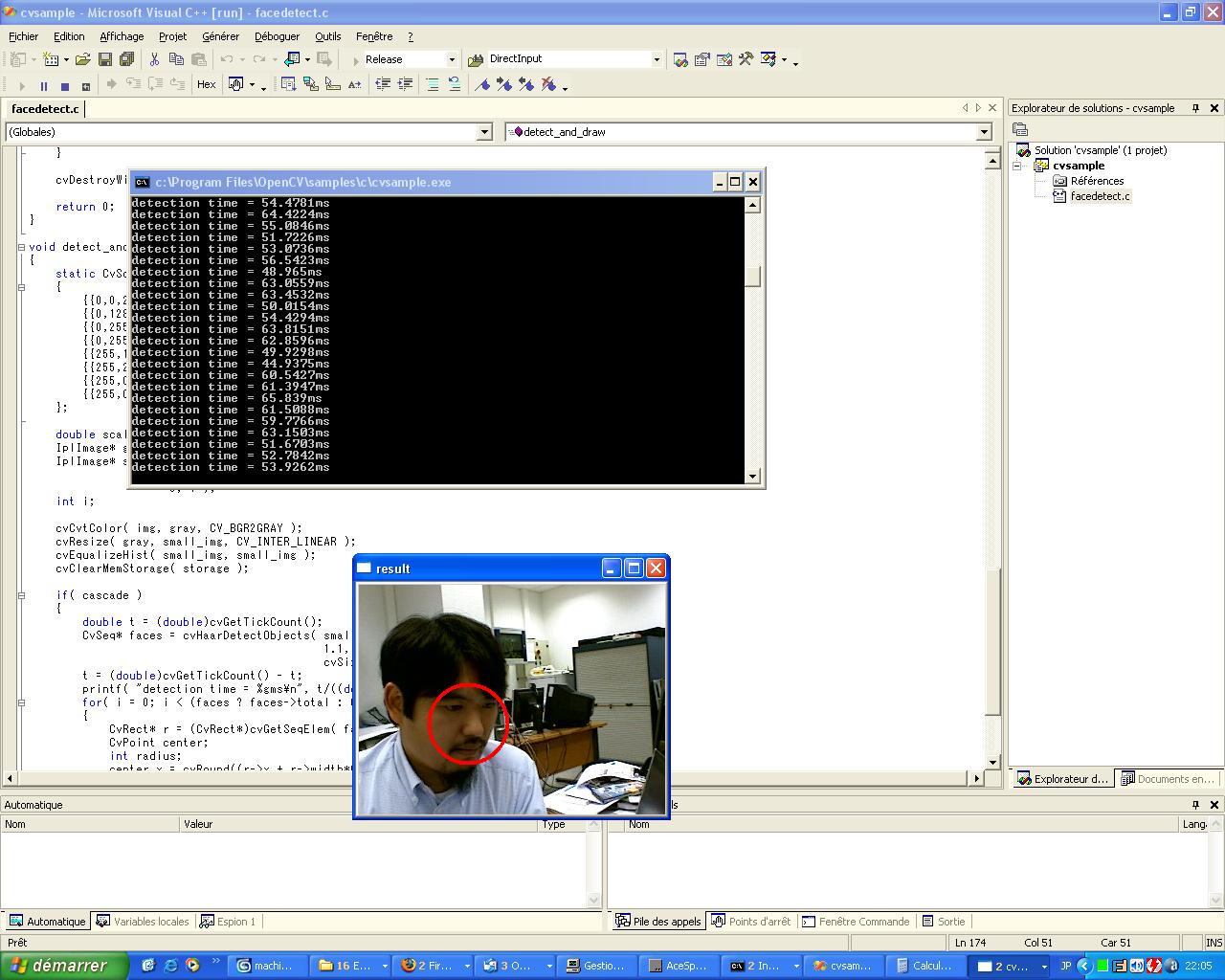
OpenCVで顔画像認識、というタイトルのエントリーを結構時間かけて、しかもスクリーンショットつきで書いていたのに、突然マウスごと止まった…。ハードディスク異常!
再起動すると、Ubuntuが起動し始めた…なんだろう?? うーん、これってハードディスクが壊れたってことか…?ってゆか、このマシンにUbuntu入れた記憶無いんですけど…と思ったらUSBハードディスクからの起動だった。すごいなDELL Dimension 9100。
とりあえず無事再起動は終わったみたいなので、被害状況を確認。
…レンダリングは駄目っぽいなあ。 書きかけのBlogは消えた。わかってはいるがつらいな。 Google Docs使うか…。
Maxの文字が日本語化けしてて驚く。多分これはさっきコントロールパネルで「非Unicodeアプリの言語設定」を変更して、そのままずっと再起動してなかったせいだと思う。
…で気を取り直して、OpenCVのほうだけど、sampleのfacedetect.cを解析中。
基本的にリビルドとかは簡単。マルチプラットフォームなライブラリにしてはずいぶんと洗練されていると思う。ディレクトリ構成なんかもちょっと癖はあるけど慣れれば分かる。 サンプルは徹底してCだし(ライブラリ内部はC++)。pythonのサンプルもある。
このサンプルはあらかじめ用意されたHaar(ハール)のClassifier Cascadeファイルを読み込んでいる。 OpenCV\data\haarcascades\haarcascade_frontalface_alt2.xml この841KBのファイルはXMLで、 「Tree-based 20x20 gentle adaboost frontal face detector.Created by Rainer Lienhart.」と書かれている。 よく見るとIntelの著作物でライセンス条文も書かれているので、勝手に製品に組み込んだりしたらまずいと思う(論文化されている)。
19のステージ、108のツリーがあって各ノードは rects2つ、tilted、threshold、left_val、right_node、stage_threshold といった構成になっている。
ウェーブレットや信号処理でよく出てくるHaar変換のパラメータ、閾値、カスケード(滝)分岐させてるためのノードという理解でいいと思う(間違ってたらごめん)。 ベクトル量子化に近い手法、キャリブレーションなしで回転や個々人の違いなどにロバストなのはすごい。 ちなみにhaarcascadesフォルダにはほかにも面白そうなプロファイルが転がっている。 以下、このファイルを元にアルゴリズムについて考察してみます。
まず「haarcascade_upperbody.xml」はETHスイスによるもので、以下の論文の実装と思われます。 「Fast and Robust Face Finding via Local Context」
この論文ではObject Centered DetectionとLocal Contextの比較を行っている。Object Centeredな顔画像認識は目→鼻→口→といった感じに認識分岐ステップをすすめていったうえで、個々の被写体に対しての処理を行うことが多いわけだけれども、提案手法はLocal Context、つまり近隣の領域との比較で認識の分岐木をすすめていく。分岐のノードは深くなるけれど、人間の顔を取り間違える可能性は低くなる。またそれぞれの人間を別に見分けることができる可能性がある。
基本的な手法は最初に挙げたRainer Lienhartの方法で「An Exteded Set of Haar-like Features for Rapid Object Detection」に書かれている。”Haar-Like”と言ってるだけにハール関数とはちょっと違う。Boosted Classifier Cascade、つまり判断結果をブーストして重み付けしていく手法。これは「Rapid Object Detection using a Boosted Cascade of Simple Features」でPaul Viola(当時MERL、現在Microsoft)がIEEE CVPR2001で報告した論文。Lienhartの方法は、同様にclassifier(クラス判別器)を、24x24、20x20といった処理ウインドウ内に収まる大量の映像で学習し(ポジティブ)、さらにまったく関係ない同サイズの背景画像などでネガティブ学習をする。Lienhartの方法は、近傍の片側に注目するEdge Features、両側に注目するLine Features、中央とその周辺に注目するCenter-surround Featuresの3種、それぞれに直交(Upright)、斜め45度(Rotated)のパターン、合計14種のフィーチャープロトタイプを用意する。パターンは白黒で領域が分けられており、おのおのポジティブ/ネガティブのウェイトをもっている(ブーストするので+1/-1ではない)。
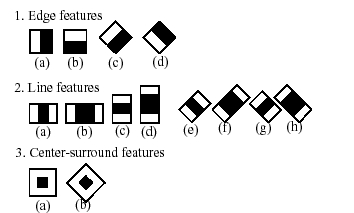
処理矩形領域の座標X,Y、長辺と短辺の長さをw,h、回転を45度単位で表現するので、例えばあるフィーチャー「座標(5,3)にある高さ2、幅6のラインフィーチャー(2a)」は
feature_I = -1 * RectSum(5,3,6,2,0°) + 3 * RectSum(7,3,2,2,0°)
というように表現できる。また、あるウィンドウサイズ内における14種のフィーチャープロトタイプのパラメータ組み合わせは有限で、論文では24x24ウインドウで合計117,941種と報告されている。
…でxmlファイルに戻るわけだけど、上記のファイルに各ステージの比較領域2つ、スレッショルドと分岐木が用意されているというわけですね。
プログラムに戻ると、 CvHaarClassifierCascade構造体にxmlファイルからロードして、キャプチャからフレーム画像を取得。
検出ルーチンでは縮小スケール(1/1.3倍)して246x184pixelsの画像にして、BGR→Grayの色変換、さらにリサイズ、EqualizeHist(ヒストグラム平滑化)を処理している(毎フレームコールするぐらいならGPUで処理したいな…)。 で肝心の顔認識だけど、
CvSeq* faces = cvHaarDetectObjects( small_img, cascade, storage, 1.1, 2, 0/*CV_HAAR_DO_CANNY_PRUNING*/, cvSize(30, 30) );
実装はOpenCV/cv/src/cvhaar.cppにある。
4番目の以降の引数はdouble scale_factor,int min_neighbors, int flags, CvSize min_sizeとなっていて、それぞれ検索窓の増分(この場合+10%ということ)、近傍ピクセルの最小値(2ピクセル以下は処理しない)、最小サイズ、となっている。flagはcanny pruningを使うかどうか、キャニーフィルターをつかった枝狩りが実装されているみたい。
コンソール画面に表示される処理速度はこの関数の実行前と実行後の間の時間。論文では320*240、全スケール検索、scale factor=1.2、Pentium4 2GHzの環境で5fpsと書かれているけれど、デフォルトのパラメータ(増分1.1、最小ピクセル2)で手元の環境では34msec出ていた。速度に関しては、例えば増分を1.2ぐらいにすると20msecを切る。CV_HAAR_DO_CANNY_PRUNINGの効果はいまいち分からなかった(深夜の研究室で一人でやってるからかも…背後に誰か検出されたら効果はあるかもしれないが、それはそれで怖いぞ)。まあ30msec出ている時点で 30FPS、16.6msec以下であれば60FPSが実現できるので、パラメータと用途によってはゲームインタフェースへの利用も可能だと思う。ともかく、この関数の場合は速度と精度を自由に設定できるのがすばらしいね。
最後にネガティブポイントを述べると、複数の顔については未検証(一人しかいないので)。でも周囲の雑音を「2人目」として検出していることもある。蛍光灯のせいもあるけど、オプティカルフローは使っていないので、複数人を検出したいなら、ほかの関数使って多少強化したらいいとおもう。そもそもグレースケールなので、顔画像なら色相-明度空間で処理すべきだ(HaarDetect自体は顔画像に限っていない)。それから「斜めの顔」は弱いと思う。アルゴリズム上45度単位でうまくとるかと思ったけど、45度を越えると、検出されないことが多い。これは学習させたデータベース(多分CMUの顔画像DB)にも関係があるのかも。AceSpeeder2モーション認識版のように頭で操作するようなアプリケーションのときは自然に±45度を越えてしまうことがあるのでカメラセットアップに注意が必要だね。あとは顔が大きく写る、精度が必要な用途には向いていないと思う。cvHaarDetectObjectsで個々の顔の粗位置を出して、そこからモーションフローを使うとよいのかもしれない。
それからGPUで実装することを考えると、いくつかやれることはあると思う。肝心の処理以前の前処理フィルタは当然として、 stage_classifierはこの場合でも19ステージ20x20程度なのであれば、もしかしたらGPU上に前処理でフィルタ化できるかもしれない。まあ思いつきで言っているところはあるけれど、処理ウィンドウが小さい処理と言うのはGPU向きなので。逆にフレーム全般において積分しまくらないといけない処理は不向きなんだけど。ふつうにフレームメモリ上にマッチングテンプレートを用意する方法よりはずっとエレガントかもしれない(ターゲット画像が与えられて、速度を重視するならその方法も否定できないけど)。